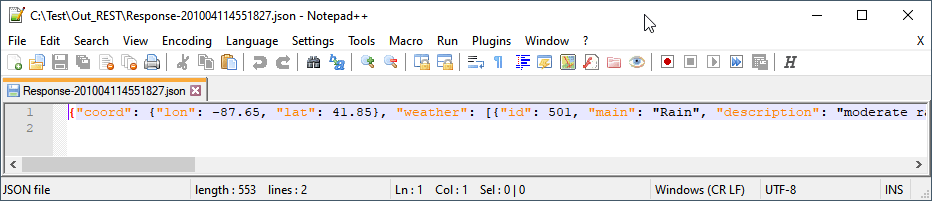
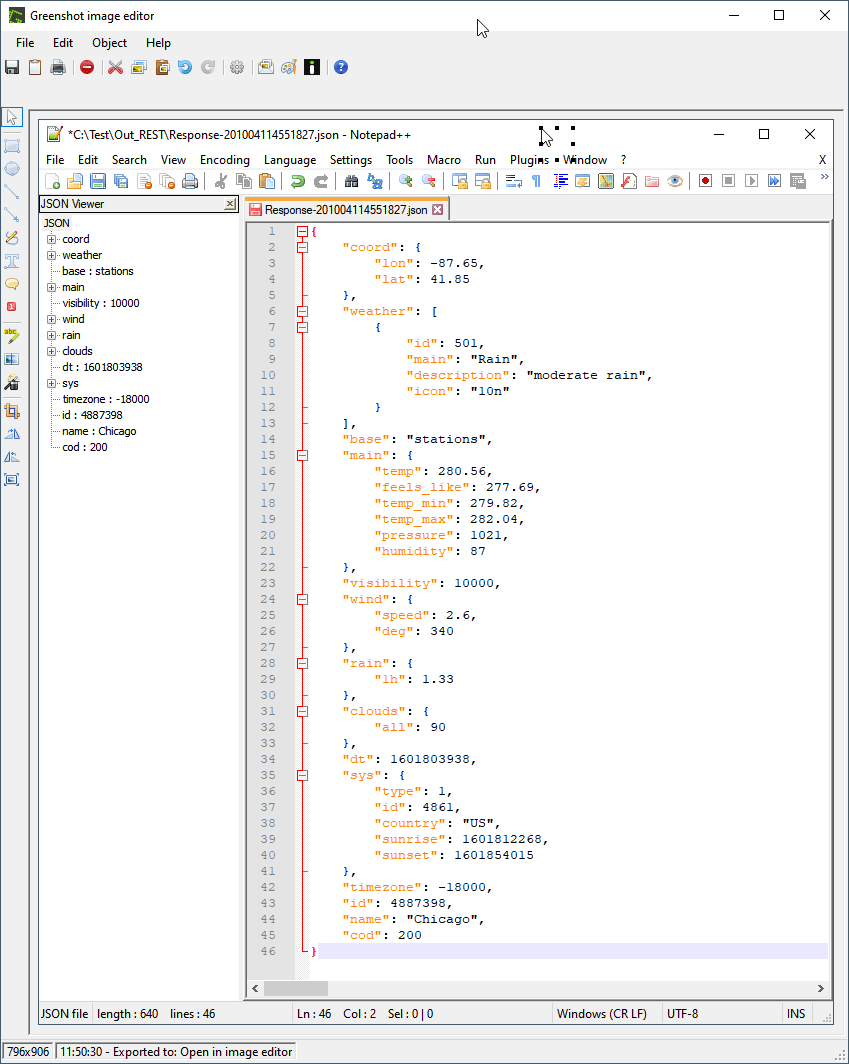
Q: I want to check the length of a filename. We have a file renaming scheme that truncates the filename to a certain max length and adds a string to keep the file unique. Is it possible to add the string only when the filename gets truncated? or alternatively create a rule that only works if the filename is shorter than say 35 characters and another roule that works on files with a longer filename.
A: Yes this is possible. We added 2 examples in this blog entry.
1. First example will use the complete filename length and 2 rules.
2. Second example will use the filename without extension and 1 rule with 2 destinations.
First Example
Please add two rules with the same source.
We used the following include filter for the first rule:
File Filter Setup > RegEx Tab > Include Filter
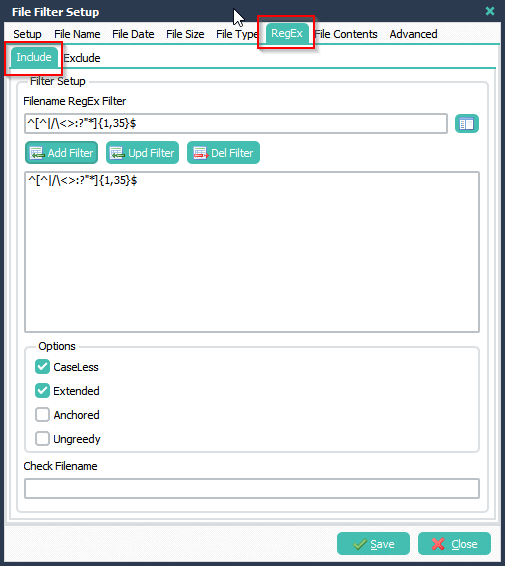
We used the following include filter for the second rule:
File Filter Setup > RegEx Tab > Include Filter
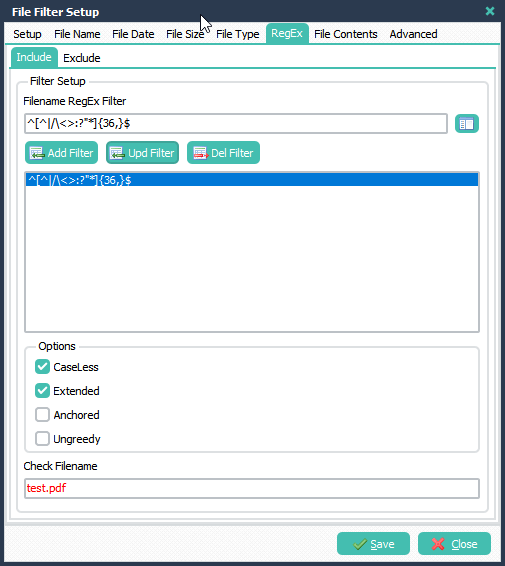
Second Example
We added a second example because the user had the following remark: “again thank you for your help the expression is working well, but it counts all the characters including the extension, I’m just trying to avoid bugs (some extensions are 3 char other are 4).”
In this second example the length of the filename without file extension will be important. We’ll use one rule with 2 destinations. Depending on the length of the filename (without extension) it will use the first or second destination.
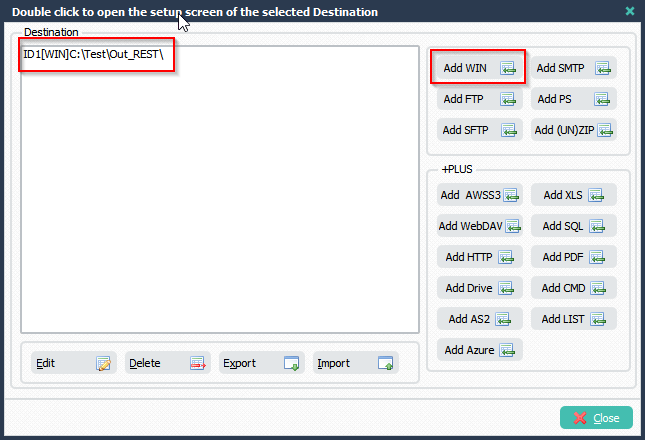
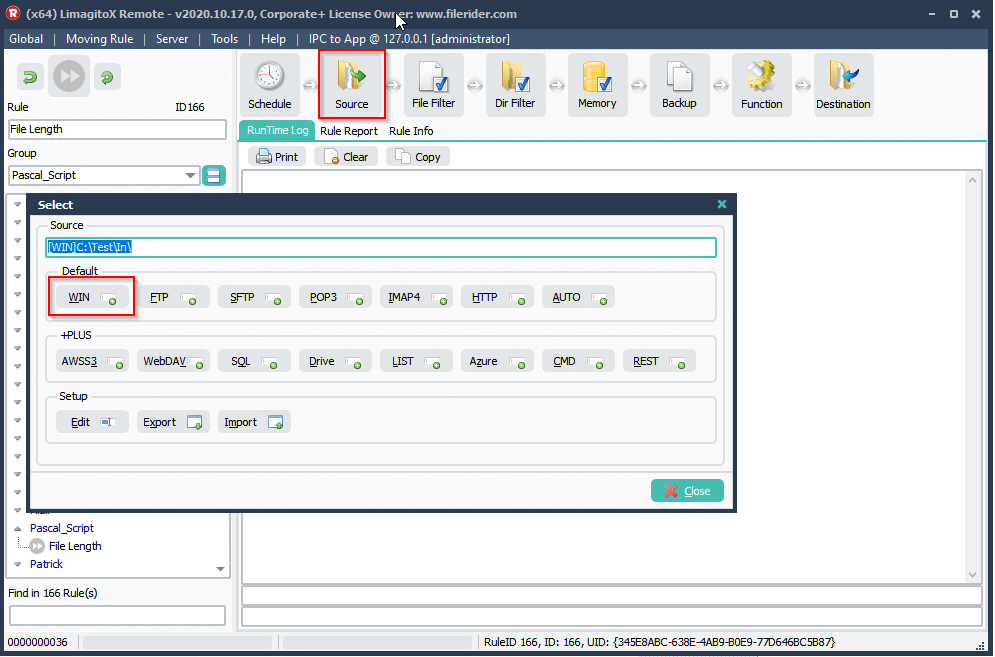
>We added a Windows folder as Source:
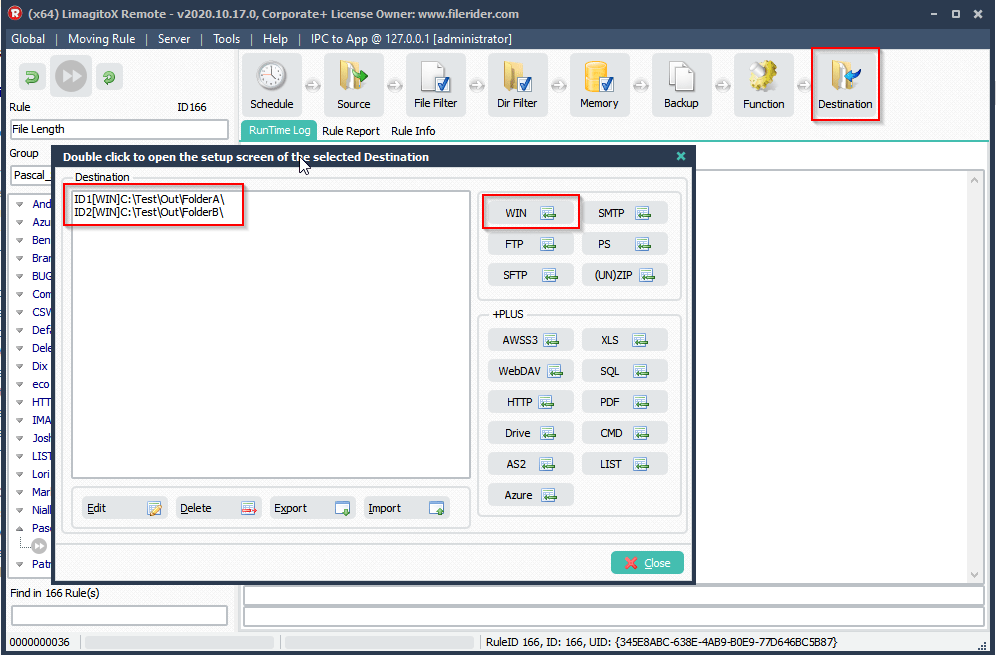
>We added two Destinations (both Windows folders). Depending on the length of the filename (without extension) it will use the first or second destination.
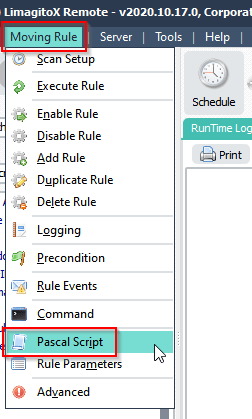
> Open ‘Pascal Script’ Setup (Moving Rule Menu item):
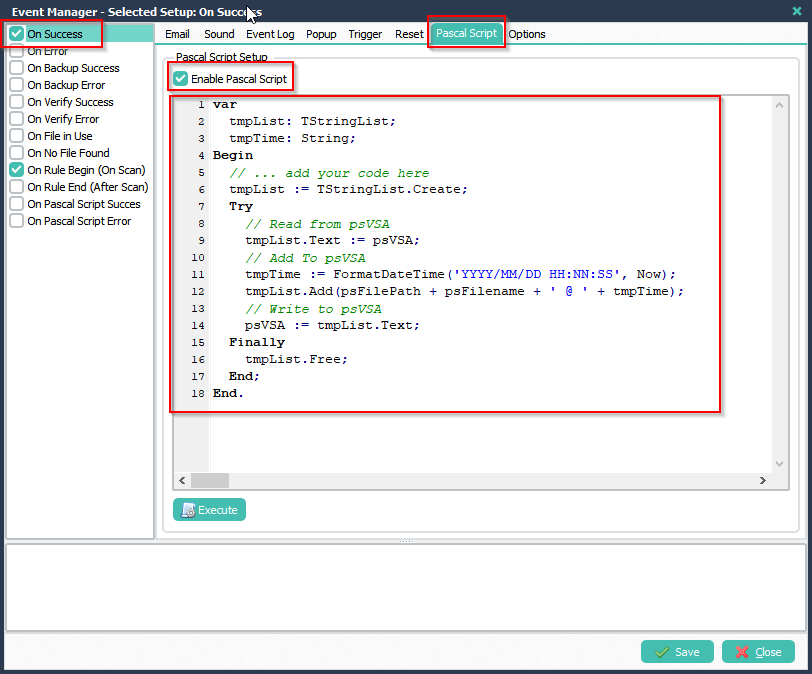
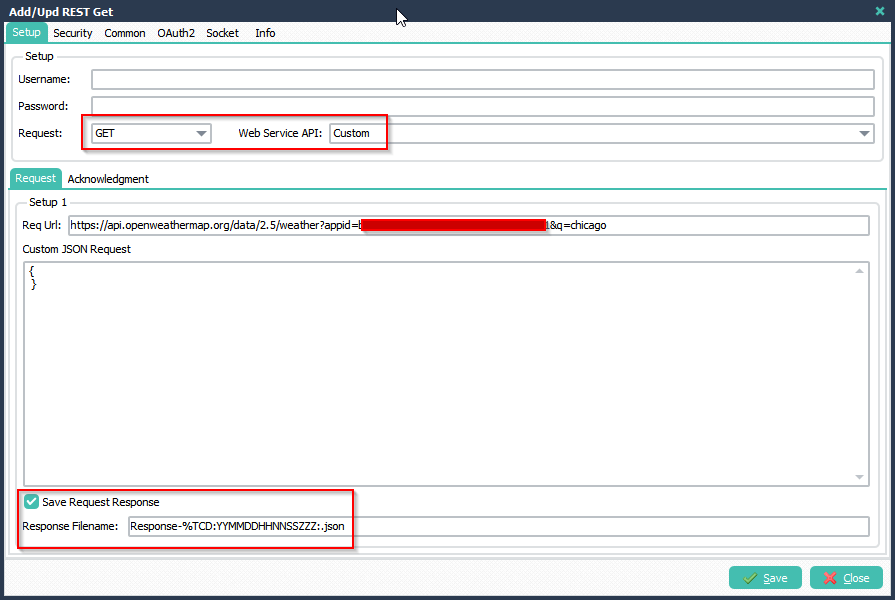
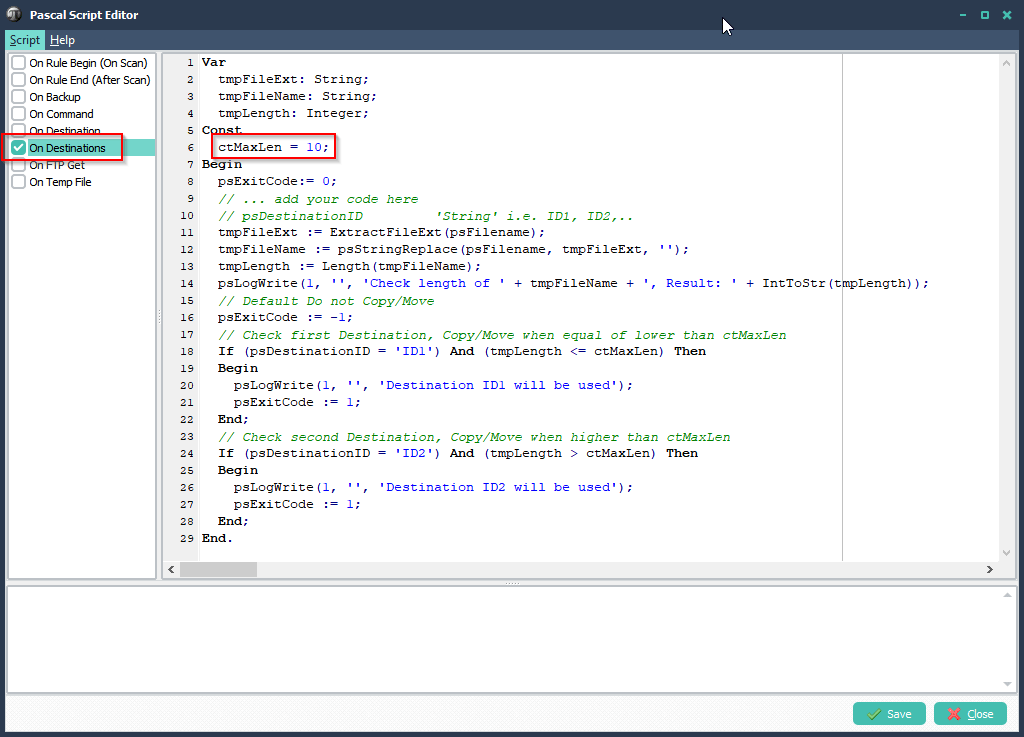
>Please add the following ‘ On Destinations‘ Pascal Script. We have set the Constant ‘ctMaxLen’ to 10 in our second example (you can change this). Filenames without extension and longer than 10 will go to the second Destination (ID2). The rest of the files will go the the first Destination (ID1).
Var
tmpFileExt: String;
tmpFileName: String;
tmpLength: Integer;
Const
ctMaxLen = 10;
Begin
psExitCode:= 0;
// ... add your code here
// psDestinationID 'String' i.e. ID1, ID2,..
tmpFileExt := ExtractFileExt(psFilename);
tmpFileName := psStringReplace(psFilename, tmpFileExt, '');
tmpLength := Length(tmpFileName);
psLogWrite(1, '', 'Check length of ' + tmpFileName + ', Result: ' + IntToStr(tmpLength));
// Default Do not Copy/Move
psExitCode := -1;
// Check first Destination, Copy/Move when equal of lower than ctMaxLen
If (psDestinationID = 'ID1') And (tmpLength <= ctMaxLen) Then
Begin
psLogWrite(1, '', 'Destination ID1 will be used');
psExitCode := 1;
End;
// Check second Destination, Copy/Move when higher than ctMaxLen
If (psDestinationID = 'ID2') And (tmpLength > ctMaxLen) Then
Begin
psLogWrite(1, '', 'Destination ID2 will be used');
psExitCode := 1;
End;
End.
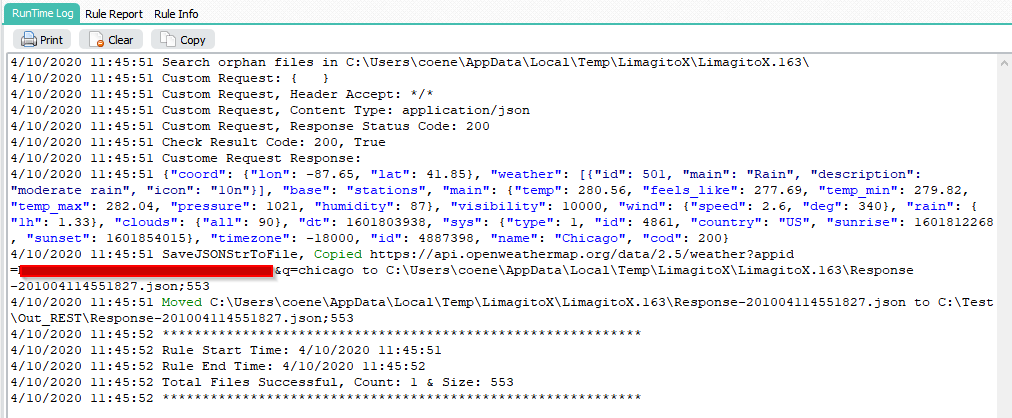
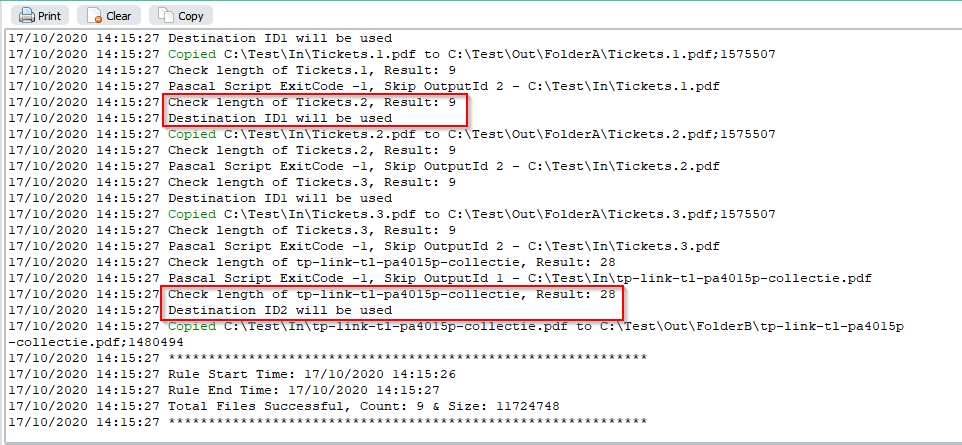
>RunTime Log result. Files longer than 10 will use the second Destination (ID2).
If you need any help with this ‘length of a filename’ request, please let us know.
Best Regards,
Limagito Team